Member-only story
Ultimate Guide for Pushing Azure SQL Changes to Dynamics 365
I recently embarked on a mission with my team to setup an integration between Azure SQL and Dynamics 365 (D365) which uses Dataverse to store its data. The requirements involved pushing any changes that take place on the Azure SQL side in real time to D365 to ensure that the data on both systems stay in sync. The solution also needed to push from Azure SQL to D365 instead of requiring the D365 side to poll for changes. Finally, the solution had to require the least amount of development effort. Here is the architecture of the solution we devised:
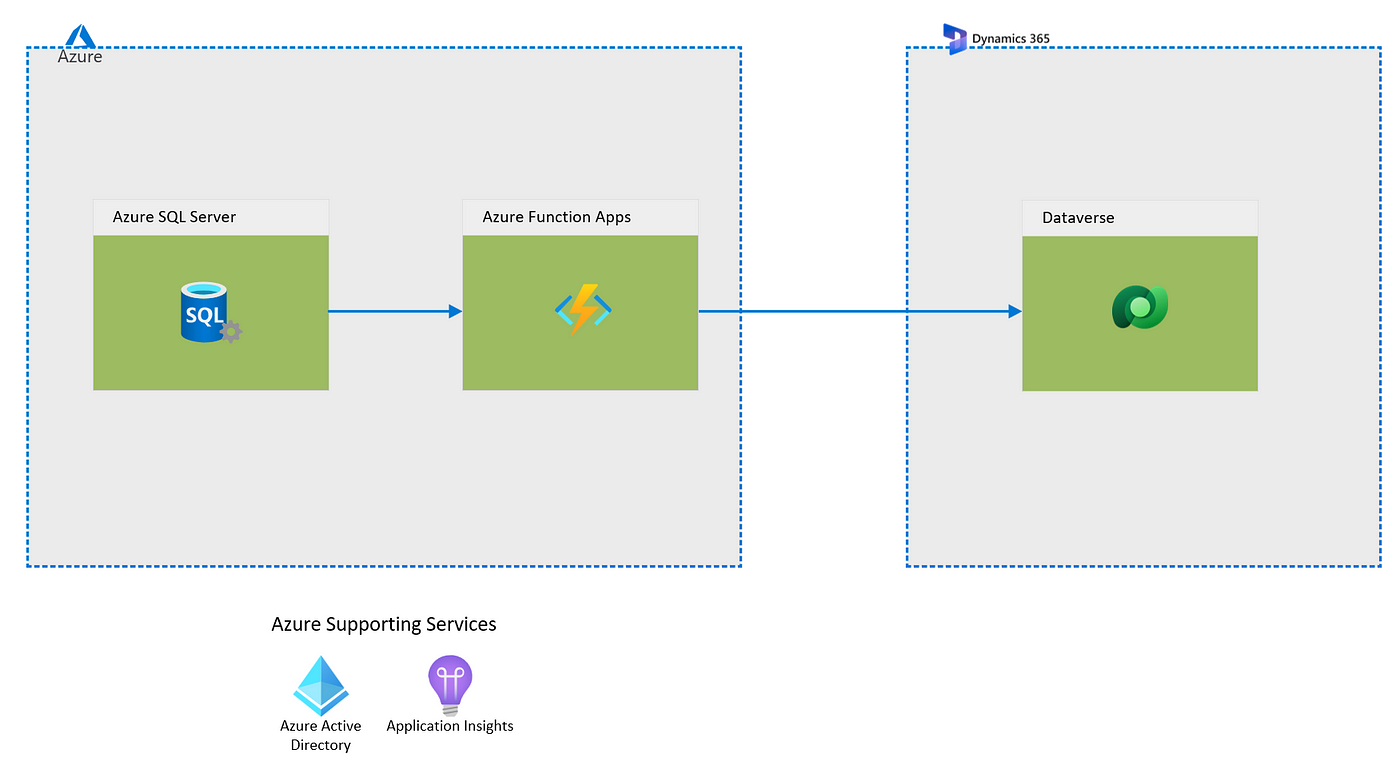
Looking at the aforementioned requirements it was clear that Azure Serverless solutions will have to come into play here. Upon further investigation we discovered that there is a new feature called Azure SQL trigger for Functions (still in public preview at the time of writing this post). As discussed here the Azure SQL trigger uses SQL change tracking functionality to monitor a SQL table for changes and trigger a function when a row is created, updated, or deleted. Now here there are couple questions that needed to be answered before adopting this solution:
- Would the solution scale?
- Would the solution be resilient?
- Would it support the latest security standards on Azure ( e.g. using Managed Identities)?
Let us discuss each of the above points in details. Whereas we would typically utilize a service bus (e.g. Azure Event Grid) to sit between the Azure SQL server and the Azure Function since a service bus like Azure Event Grid automatically adjusts the rate at which events are delivered to a function based on the perceived rate at which the function can process events, it turns out that with Azure SQL trigger for Functions , the functions can scale automatically based on the amount of changes that are pending to be processed in the user table as shown here. Thus, the solution can achieve scale even without the presence of a service bus.
The next point we had to address was resiliency. Well, the system builds on the infrastructure provided by SQL change tracking. The general idea is that the Azure SQL trigger keeps track of the last synced state which is the last change the function have processed. So, if a function was to go down and another instance…
